Any non-zero recurrent_dropout yields NaN losses and weights; latter are either 0 or NaN. Happens for stacked, shallow, stateful, return_sequences = any, with & w/o Bidirectional(), activation='relu', loss='binary_crossentropy'. NaNs occur within a few batches.
Any fixes? Help's appreciated.
TROUBLESHOOTING ATTEMPTED:
recurrent_dropout=0.2,0.1,0.01,1e-6kernel_constraint=maxnorm(0.5,axis=0)recurrent_constraint=maxnorm(0.5,axis=0)clipnorm=50 (empirically determined), Nadam optimizer activation='tanh' - no NaNs, weights stable, tested for up to 10 batcheslr=2e-6,2e-5 - no NaNs, weights stable, tested for up to 10 batcheslr=5e-5 - no NaNs, weights stable, for 3 batches - NaNs on batch 4batch_shape=(32,48,16) - large loss for 2 batches, NaNs on batch 3
NOTE: batch_shape=(32,672,16), 17 calls to train_on_batch per batch
ENVIRONMENT:
- Keras 2.2.4 (TensorFlow backend), Python 3.7, Spyder 3.3.7 via Anaconda
- GTX 1070 6GB, i7-7700HQ, 12GB RAM, Win-10.0.17134 x64
- CuDNN 10+, latest Nvidia drives
ADDITIONAL INFO:
Model divergence is spontaneous, occurring at different train updates even with fixed seeds - Numpy, Random, and TensorFlow random seeds. Furthermore, when first diverging, LSTM layer weights are all normal - only going to NaN later.
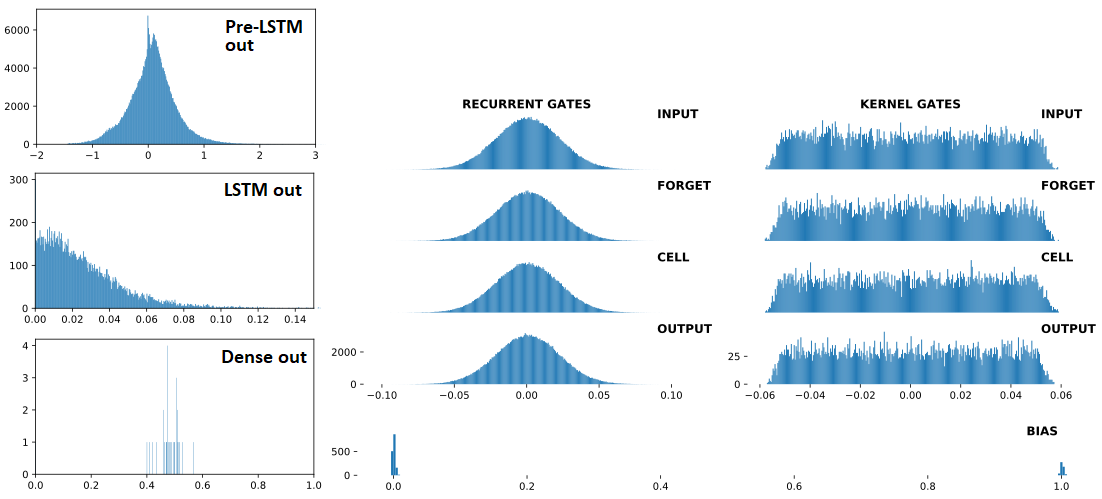
Below are, in order: (1) inputs to LSTM; (2) LSTM outputs; (3) Dense(1,'sigmoid') outputs -- the three are consecutive, with Dropout(0.5) between each. Preceding (1) are Conv1D layers. Right: LSTM weights. "BEFORE" = 1 train update before; "AFTER = 1 train update after
BEFORE divergence:
AT divergence:
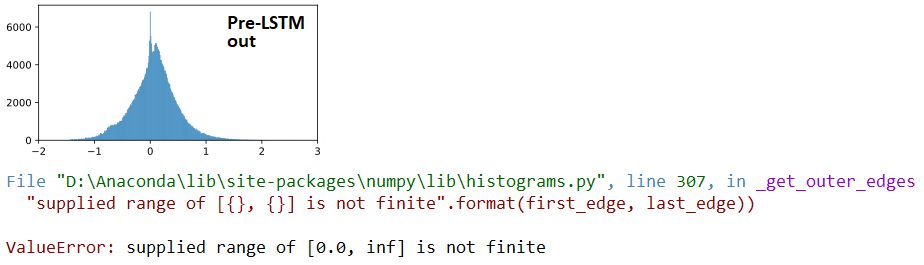
## LSTM outputs, flattened, stats
(mean,std) = (inf,nan)
(min,max) = (0.00e+00,inf)
(abs_min,abs_max) = (0.00e+00,inf)
AFTER divergence:
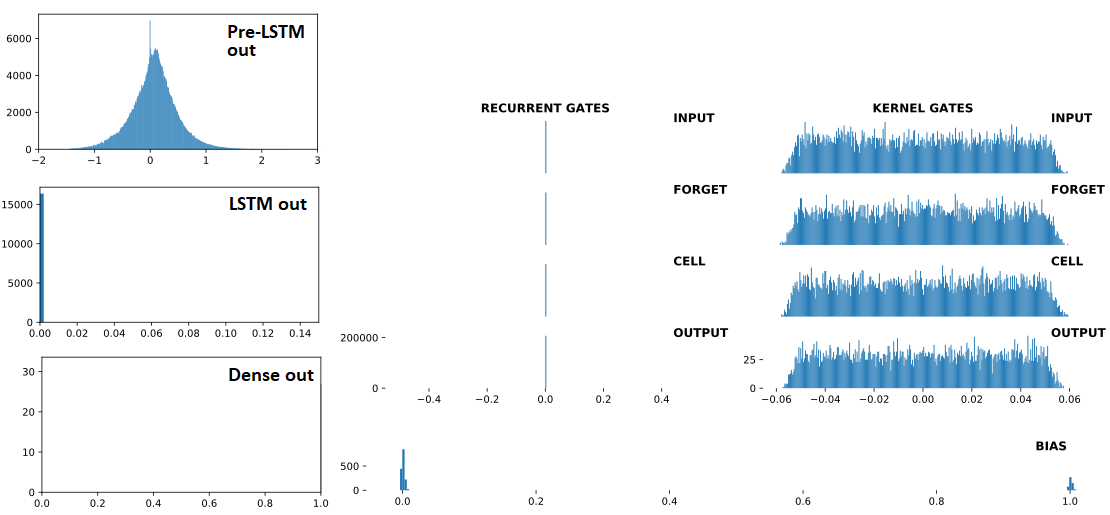
## Recurrent Gates Weights:
array([[nan, nan, nan, ..., nan, nan, nan],
[ 0., 0., -0., ..., -0., 0., 0.],
[ 0., -0., -0., ..., -0., 0., 0.],
...,
[nan, nan, nan, ..., nan, nan, nan],
[ 0., 0., -0., ..., -0., 0., -0.],
[ 0., 0., -0., ..., -0., 0., 0.]], dtype=float32)
## Dense Sigmoid Outputs:
array([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]], dtype=float32)
MINIMAL REPRODUCIBLE EXAMPLE:
from keras.layers import Input,Dense,LSTM,Dropout
from keras.models import Model
from keras.optimizers import Nadam
from keras.constraints import MaxNorm as maxnorm
import numpy as np
ipt = Input(batch_shape=(32,672,16))
x = LSTM(512, activation='relu', return_sequences=False,
recurrent_dropout=0.3,
kernel_constraint =maxnorm(0.5, axis=0),
recurrent_constraint=maxnorm(0.5, axis=0))(ipt)
out = Dense(1, activation='sigmoid')(x)
model = Model(ipt,out)
optimizer = Nadam(lr=4e-4, clipnorm=1)
model.compile(optimizer=optimizer,loss='binary_crossentropy')
for train_update,_ in enumerate(range(100)):
x = np.random.randn(32,672,16)
y = np.array([1]*5 + [0]*27)
np.random.shuffle(y)
loss = model.train_on_batch(x,y)
print(train_update+1,loss,np.sum(y))
Observations: the following speed up divergence:
- Higher
units (LSTM)
- Higher # of layers (LSTM)
- Higher
lr << no divergence when <=1e-4, tested up to 400 trains
- Less
'1' labels << no divergence with y below, even with lr=1e-3; tested up to 400 trains
y = np.random.randint(0,2,32) # makes more '1' labels
UPDATE: not fixed in TF2; reproducible also using from tensorflow.keras imports.
See Question&Answers more detail:
os 


