|
从网上也能搜罗到很多介绍SVM的文章,绝大多数文章主要集中在介绍SVM的原理,一般人或者没有基础的人阅读起来非常费劲,反而更增加了SVM了解的难度。但是对于很多学习者来说,更多的是想明白其设计的基本原理,了解其优缺点,以及具体怎么利用SVM来解决实际问题。本文就是期望能介绍清楚这些内容。 历史 SVM的一些基本概念其实提出来很早。早在1963年,数学家Vapnic等人在研究模式识别问题时就提出了支撑向量的概念,核心思想就是作为支撑向量的样本会对识别的问题起到关键性的作用。据传闻,也正是Vapnic发明的SVM的基本算法,使得神经网络的研究声势就此衰落了10年。
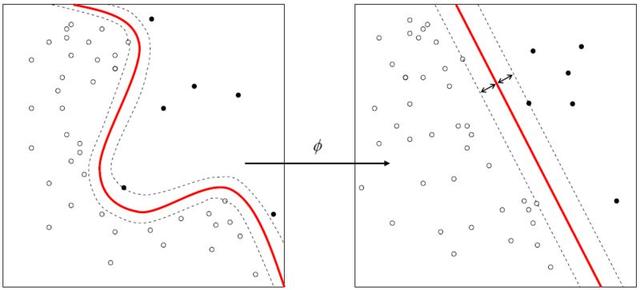
由于SVM在手写识别等领域取得了非同凡响的效果,研究者越来越多,也使得该算法出现了更多衍伸版,用来解决不同的问题,比如1971年,Kimeldorf提出了基于支撑向量构建核空间的方法。后来Vapnic等人正式提出相关的统计学习理论。 SVM本身是一个线性分类器,最开始解决的是线性可分的问题,然后拓展到非线性可分的问题,甚至扩展到非线性函数中去。解决线性不可分的方法,主要是利用非线性映射将低维空间内不可分的样本映射成高纬空间线性可分的样本。然后如线性可分一般,计算一个超平面将样本分成两类。
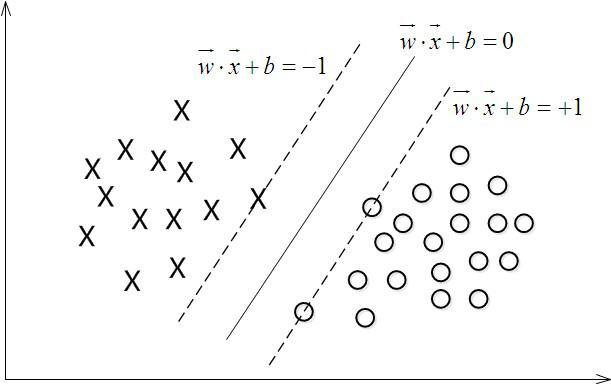
原理 机器学习相关教程中会详细介绍SVM原理,各种线性代数的变化。抛开具体的数学公式,SVM的基本原理还是比较简单,就是找到一个超平面,能将数据进行有效的分类,同时保证超平面两边的样本尽可能远的距离这个超平面。
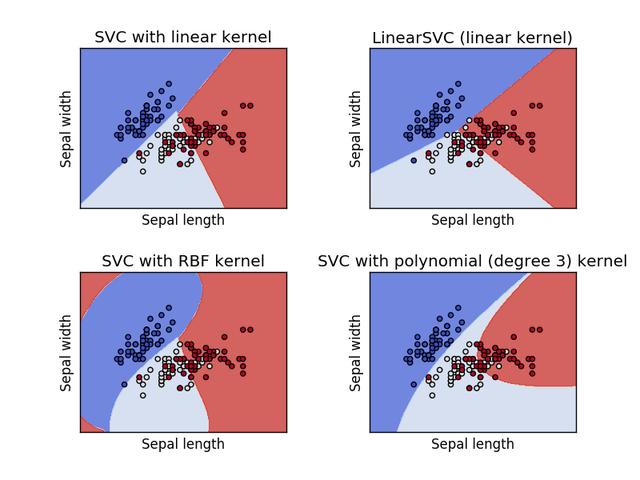
另外一个重要的概念就是支撑向量(也就是其名字的起源)。如上图所示,实线部分即是我们要寻找的超平面,既然SVM的目的就是为了使两边分类的点尽可能的远离超平面,那么也就是要保证虚线部分的点尽可能原理即可。而这些虚线上的点即为支撑向量。 这里又引入了一个概念,离超频面的距离。距离的概念有很多种,在SVM中主要需要使用几何距离。经过一系列推导(感兴趣的同学可以翻相关书籍),几何距离即是,W*X+B/|W|。也就使得SVM的问题转换成在f(x)=W*X+B一定约束的情况下,|W|最小。 一般情况,SVM原理明白到这也就够了,但有些为了自己实现SVM,还需要了解到上面问题的求解,以及线性扩展到非线性问题,这要用到拉格朗日对偶性方面的原理了。这里也就不再深入了,毕竟我们的重点是在理解一定原理的基础上解决实际问题。 优缺点 其优点总结如下: 即使在高纬度空间,也有很好的适用性 在纬数远远高于样本数的情况下,也能适用 仅仅需要样本的一部分(支撑向量)就可以建立分类模型,相比KNN等方法内存等资源开销更小 由于可以指定核函数(Kimeldorf等完善的),可以处理很多种场景,不同核函数能达到不同效果 但其也有明显缺点: 如果特征数目过分多于样本数目,效果则会有所下降 概率评估的开销非常大 实例 这里仍然以scikit-learn作为工具,并介绍其使用的例子。 Scikit-learn中支持三种SVM分类算法:SVC,NuSVC,LinerSVC。SVC和NuSVC非常相似,而LinerSVC最大的区别在于其不能指定核函数,只能依照其默认的线性核函数来工作。从其官方例子,可以看出SVC指定线性核函数,其效果和LinerSVC是接近的。
和“机器学习就是这么简单 之 聚类算法实现”中的聚类算法类似,scikit-learn中各种SVC支持的输入主要是numpy.narray格式,而与聚类算法不同的时,由于SVM主要是一个监督型的学习算法,其还需要输入每个样本对应的lable,通过fit接口传入数据:fit(x, y, [weight])。 对应与上图的代码如下: import numpy as np import matplotlib.pyplot as plt from sklearn import svm, datasets #导入iris库数据 iris = datasets.load_iris() X = iris.data[:, :2] y = iris.target C = 1.0 # 归一化参数 svc = svm.SVC(kernel=’linear’, C=C).fit(X, y) rbf_svc = svm.SVC(kernel=’rbf’, gamma=0.7, C=C).fit(X, y) poly_svc = svm.SVC(kernel=’poly’, degree=3, C=C).fit(X, y) lin_svc = svm.LinearSVC(C=C).fit(X, y) #创建网格型画布 h = .02 # 各网格中的距离 x_min, x_max = X[:, 0].min() – 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() – 1, X[:, 1].max() + 1 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) titles = [‘SVC with linear kernel’, ‘LinearSVC (linear kernel)’, ‘SVC with RBF kernel’, ‘SVC with polynomial (degree 3) kernel’] #画图相关 for i, clf in enumerate((svc, lin_svc, rbf_svc, poly_svc)): plt.subplot(2, 2, i + 1) plt.subplots_adjust(wspace=0.4, hspace=0.4) Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.8) plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm) plt.xlabel(‘Sepal length’) plt.ylabel(‘Sepal width’) plt.xlim(xx.min(), xx.max()) plt.ylim(yy.min(), yy.max()) plt.xticks(()) plt.yticks(()) plt.title(titles[i]) plt.show() 除了上面简单的例子,scikit-learn中的SVM算法也能很好的处理样本不平衡、多分类等等问题。 |

2023-10-27
2022-08-15
2022-08-17
2022-09-23
2022-08-13

六六分期app的软件客服如何联系?不知道吗?加qq群【895510560】即可!标题:六六分期
今天小编告诉大家如何处理win10系统火狐flash插件总是崩溃的问题,可能很多用户都不知

今天小编告诉大家如何对win10系统删除桌面回收站图标进行设置,可能很多用户都不知道
今天小编告诉大家如何对win10系统电脑设置节能降温的设置方法,想必大家都遇到过需要
我们在使用xp系统的过程中,经常需要对xp系统无线网络安装向导设置进行设置,可能很多
今天小编告诉大家如何处理win7系统玩cf老是与主机连接不稳定的问题,可能很多用户都不
电脑对日常生活的重要性小编就不多说了,可是一旦碰到win7系统设置cf烟雾头的问题,很
我们在日常使用电脑的时候,有的小伙伴们可能在打开应用的时候会遇见提示应用程序无法
今天小编告诉大家如何对win7系统打开vcf文件进行设置,可能很多用户都不知道怎么对win
今天小编告诉大家如何对win10系统s4开启USB调试模式进行设置,可能很多用户都不知道怎