









|
中文分词算法有哪些
中文分词算法小结
英语文字词与词中间以空格符隔开,便捷电子计算机鉴别,可是中文以字为企业,语句全部字连起來才可以表述一个详细的含意。如英语“Iamwritingablog”,英文词与词中间有空格符开展分隔,而相匹配的中文“我还在写文章赚钱”,全部的词连在一起,电子计算机能非常容易的鉴别“blog”是一个英语单词,而难以了解“博”、“客”是一个词,因而对中文文字编码序列开展分割的全过程称之为“分词”。中文分词算法是自然语言的基本解决方案,常用于百度搜索引擎、广告、强推荐、问答系统软件。
从不一样的视角对待中文语句,将会使中文分词每日任务(CWS)的规范彻底不一样。比如「冠军」既能够当做单独的词,也可以了解为「总」和「总冠军」2个词。之前这类状况十分难处理,大家只有定一些词典或标准来提升这种词的区划。
但这种应该是分词实体模型应当得学的呀,我们不能只关心分词实体模型在单一规范中的主要表现,还必须关心不一样分词规范中的相互特点。这种相互特点才算是实体模型必须重中之重学习培训的,他们能搭建更有效的分词結果。
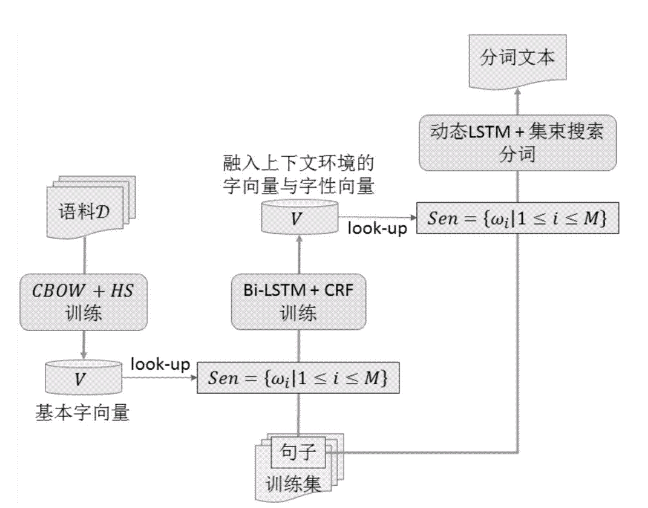
1.根据字典(字符串匹配,机械设备分词)
界定:依照一定对策将待剖析的中国汉字串与一个“大设备字典”中的百度词条开展匹配,若在字典中寻找某一字符串数组,则匹配取得成功。
依照扫描仪方位的不一样:顺向匹配和逆向匹配
依照长短的不一样:较大 匹配和最少匹配
1.1顺向较大 匹配观念MM
1》从从左往右取待分割中文句的m字符做为匹配字段名,中文分词m为大设备字典中最多百度词条数量。
2》搜索大设备字典并开展匹配。如果匹配成功,匹配字段名称将作为单词分割。
如果匹配失败,match字段名的最后一个单词将被删除,剩下的字符串数组将被用作新的匹配字段名,匹配过程将被重复到所有单词被分离。
wps_clip_image-18766
1.2逆向较大 匹配优化算法RMM
该优化算法是顺向较大 匹配的逆向逻辑思维,匹配失败,将匹配字段名的最前一个字除掉,试验说明,逆向较大 匹配优化算法要好于顺向较大 匹配优化算法。
1.3双重较大 匹配法(Bi-directctionMatchingmethod,BM)
双重较大 匹配法是将顺向较大 匹配法获得的分词結果和逆向较大中文分词匹配法的到的結果开展较为,进而决策恰当的分词方式。据SunM.S.和BenjaminK.T.(1995)的研究表明,中文中90.0%上下的语句,顺向较大 匹配法和逆向较大 匹配法彻底重叠且恰当,仅有大约9.0%的语句二种分割方式获得的結果不一样,但在其中必有一个是恰当的(模棱两可检验取得成功),仅有不上1.0%的语句,或是顺向较大 匹配法和逆向较大 匹配法的分割虽重叠确是错的,或是顺向较大 匹配法和逆向较大中文分词匹配法分割不一样但2个也不对(模棱两可检验不成功)。这更是双重较大 匹配法在好用中文数据分析系统中足以普遍应用的缘故所属。
1.4开设分割标示法
搜集分割标示,在全自动分词前解决分割标示,再用MM、RMM开展细生产加工。
1.5最好匹配(OM,分顺向和逆向)
对分词字典按词频尺寸排列顺序,并标明长短,减少算法复杂度。
优势:便于完成
缺陷:匹配速度比较慢。针对未登录词的填补较难完成。欠缺自学习培训。
2根据统计分析的分词(无词典分词)
关键观念:前后文中,邻近的字另外出現的频次越多,中文分词就越将会组成一个词。因而字与字邻近出現的几率或頻率能不错的体现词的真实度。
关键的统计模型是n-gram和隐马尔可夫模型(hmm)。
2.1N-gram实体模型观念
实体模型根据那样一种假定,第n个词的出現只与前边N-一个词有关,而与其他一切词用不有关,全句的几率便是每个词出現几率的相乘.
大家给出一个词,随后猜想下一个词是什么。当我讲“艳照门”这个词时,你想起下一个词是什么呢?我觉得大伙儿很有可能会想起“冠希哥”,大部分不容易有些人会想起“陈志杰”吧。N-gram实体模型的关键观念就这样的。
针对一个语句T,大家怎么计算它出現的几率呢?假定T是由词编码序列W1,W2,W3,…Wn构成的,那麼P(T)=P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
可是这类方式存有2个致命性的缺点:一个缺点是主要参数室内空间过大,中文分词不太可能产品化;此外一个缺点是数据信息稀少比较严重。
以便处理这个问题,大家引进了马尔科夫假定:一个词的出現只是取决于它前边出現的比较有限的一个或是好多个词。
假如一个词的出現仅取决于它前边出現的一个词,那麼大家就称作bigram。即
P(T)=P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
≈P(W1)P(W2|W1)P(W3|W2)…P(Wn|Wn-1)
假如一个词的出現仅取决于它前边出現的2个词,那麼大家就称作trigram。
结合实际用的数最多的便是bigram和trigram了,并且实际效果很非常好。高过四元的用的非常少,由于训炼它必须更巨大的语料库,并且数据信息稀少比较严重,算法复杂度高,精密度却提升的很少。
设w1,w2,w3,...,wn是长短为n的字符串数组,要求随意词wi只与它的前2个有关,中文分词获得三元概率模型
wps_clip_image-20787
依此类推,N元实体模型便是假定当今词的出現几率只同它前边的N-一个词相关。
2.2隐马尔科夫实体模型观念
3根据标准的分词(根据词义)
根据模拟人对语句的了解,做到鉴别词的实际效果,基础观念是文本挖掘,句法分析,中文分词运用语法信息内容和词义信息内容对文字开展分词。全自动逻辑推理,并进行对未登录词的填补是其优势。不成熟.
实际定义:有限状态机英语的语法约束矩阵特点词典
4根据字标明的中文分词方式
过去的分词方式,不论是根据标准的還是根据统计分析的,一般都取决于一个事前定编的词汇表(字典)。中文分词全自动分词全过程便是根据词汇表和基本信息来作出词语切分的管理决策。再者就是,根据字标明的分词方式事实上是构词方式。即把分词全过程视作字在字串中的标明难题。因为每一个字在结构一个特殊的词句时都占有着一个明确的构词部位(即词位),倘若要求每一个字数最多仅有四个构词部位:即B(词首),M(词中),E(词尾)和S(独立成词),那麼下边语句(甲)的分词結果就可以立即表明成如(乙)所显示的逐句标明方式:
(甲)分词結果:/上海市/方案/N/本/新世纪/末/完成/平均/中国/生产制造/总价值/五千美金/
(b)标记方式:上/B海/E计划/B计划/EN/S本/s世纪/E终端/s实际/B现/E人/B平均/E国/B内/E产/E总/B值/EN/S千/M美元/E。/S
最先必须表明,这儿说到的“字”不只仅限于中国汉字。充分考虑中文真正文字中难以避免会包括一定总数的非中国汉字标识符,文中常说的“字”,也包含外语英文字母、阿拉伯数和标点等标识符。全部这种标识符全是构词的基础模块。自然,中文分词中国汉字仍然是这一模块结合中总数数最多的一类标识符。
把分词全过程视作字的标明难题的一个关键优点取决于,它可以均衡地对待词汇表词和未登录词的鉴别难题。在这类分词技术性中,文字中的词汇表词和未登录词全是用统一的字标明全过程来完成的。在学习培训构架上,既能够无须专业注重词汇表词信息内容,也无需专业设计方案特殊的未登录词(如姓名、地名大全、组织名)鉴别控制模块。这促使分词系统软件的设计方案大大简化。在字标明全过程中,所有的字依据预订义的特点开展词位特点的学习培训,得到一个概率模型。随后,在待分字串上,依据字与字中间的融合密不可分水平,获得一个词位的标明結果。最终,依据词位界定立即得到最后的分词結果。总得来说,在那样一个分词全过程中,分词变成字资产重组的简易全过程。殊不知这一简易解决产生的分词結果确是比较满意的。
因为很多中小企业都是SEO的自由撰稿人,所以此时只要理解分词算法的基本原理的简单应用在工作中更加轻松有效,中文分词如果企业有专业的打火机,此时我们就不要应用熟练的分词算法的基本原理。只要自己拥有足够的认知能力,就能在有效的具体指导下,在写作者写文章内容时有效地展开关键词布局,形成写作者分词的合理布局观念。否则,只有专业的技术写作人员才能把文章写得分而不精,这样写出来的文章既不能满足SEO细分的要求,也降低了客户体验。融合当今中文分词技术性先在丈信息资源管理等行业的广泛运用,剖析了中丈分词技术性的必要性,对三类基础分词算法开展了详细介绍并探讨了分别的特.点,明确提出了中文分词技术性遭遇的难点及汁其将来的未来展望。
归纳如下:最先依据切分标记将查寻分离,随后看一下是不是有反复的字符串数组,如果有,就抛下不必要的,只保存一个,然后分辨是不是有英文或是数据,如果有得话,把英语或是数据作为一个总体保存并把前后左右的中文割开。 |

2023-10-27
2022-08-15
2022-08-17
2022-09-23
2022-08-13

六六分期app的软件客服如何联系?不知道吗?加qq群【895510560】即可!标题:六六分期
今天小编告诉大家如何处理win10系统火狐flash插件总是崩溃的问题,可能很多用户都不知

今天小编告诉大家如何对win10系统删除桌面回收站图标进行设置,可能很多用户都不知道
今天小编告诉大家如何对win10系统电脑设置节能降温的设置方法,想必大家都遇到过需要
我们在使用xp系统的过程中,经常需要对xp系统无线网络安装向导设置进行设置,可能很多
今天小编告诉大家如何处理win7系统玩cf老是与主机连接不稳定的问题,可能很多用户都不
电脑对日常生活的重要性小编就不多说了,可是一旦碰到win7系统设置cf烟雾头的问题,很
我们在日常使用电脑的时候,有的小伙伴们可能在打开应用的时候会遇见提示应用程序无法
今天小编告诉大家如何对win7系统打开vcf文件进行设置,可能很多用户都不知道怎么对win
今天小编告诉大家如何对win10系统s4开启USB调试模式进行设置,可能很多用户都不知道怎






