









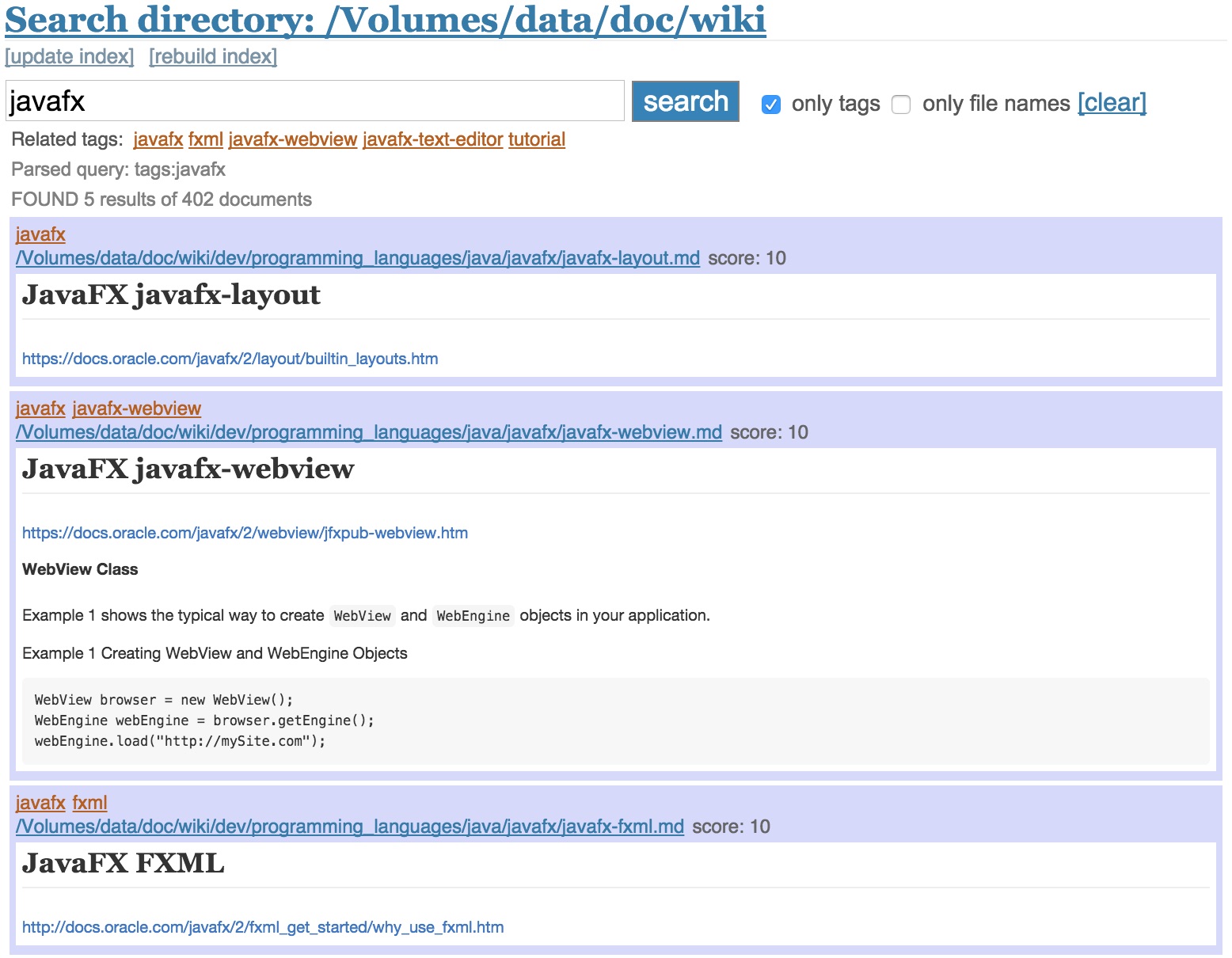
开源软件名称(OpenSource Name):BernhardWenzel/markdown-search开源软件地址(OpenSource Url):https://github.com/BernhardWenzel/markdown-search开源编程语言(OpenSource Language):Python 44.6%开源软件介绍(OpenSource Introduction):Search engine for local markdown files with taggingThis is a local search engine takes advantage of markdown syntax by giving boost to words in headlines, emphasis and other markup. One special feature is that it treats the first line of a markdown file as a list of tags (this behaviour is configurable, the tags line can be prefixed with a term or switched off). Implemented in Python using Flask, Whoosh and Mistune. InstallationClone/fork project. Rename The search engine will index all files in this folder and it's subdirectories. Install the Python requirements. Preferably in a virtualenv, run Run search engineJust run UsageBuild/update indexClick on the TagsThe first line of a markdown file is treated as a list of tags. How tags are stored can be configured by changing the regex in Tags can be switched off or can be prefixed (e.g. "tags:"). If prefixed, the line with the tags definitions can be anywhere in the file. Choose only nouns as tags (recommended)To enable it, uncomment lines 71-79 in This requires to have Download the module using Python console. Show all tagsWhen going to the starting page or when clicking on
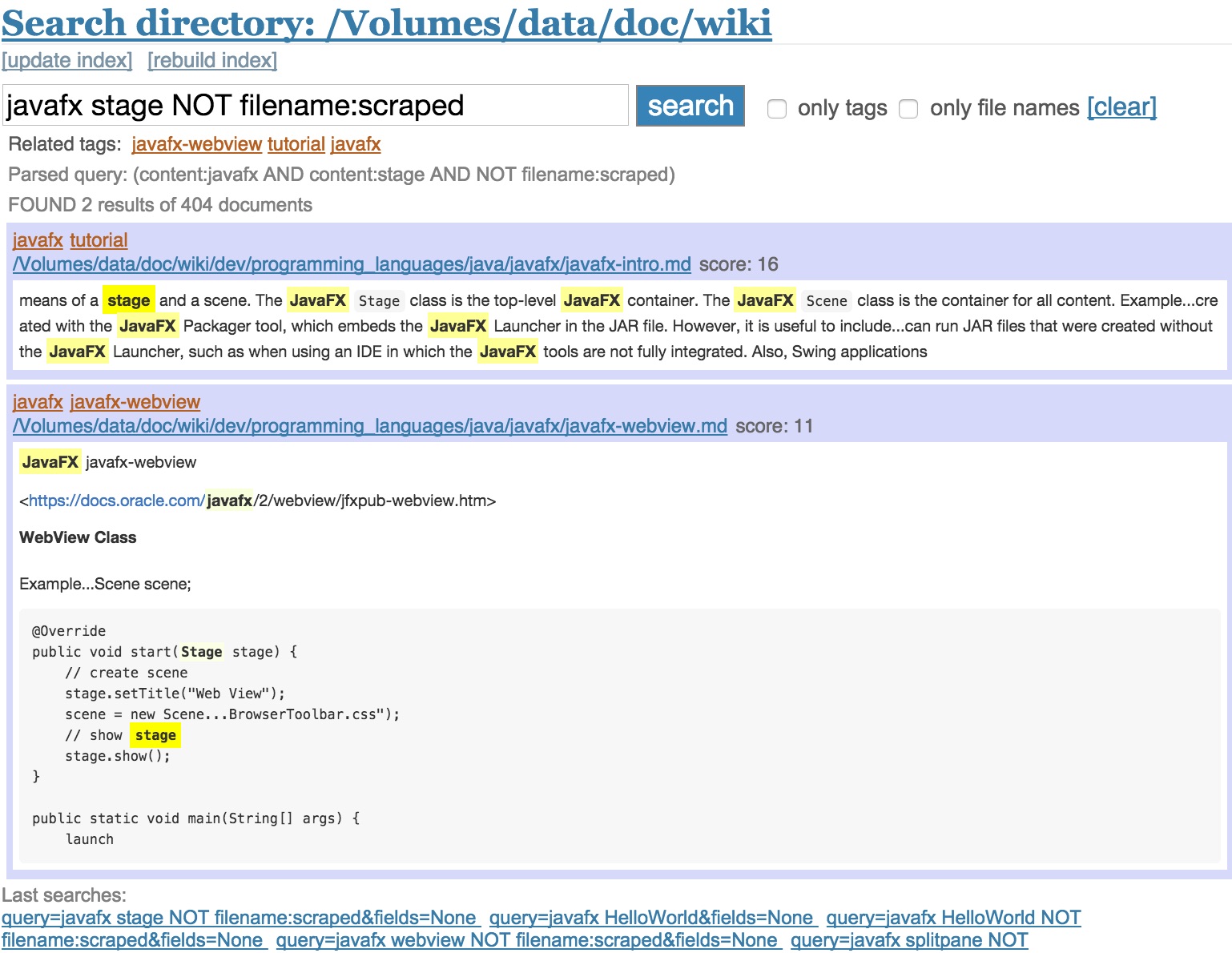
SearchingType in the query as you would in any other search engine. The syntax is defined by the Whoosh library (https://whoosh.readthedocs.io/en/latest/querylang.html). It is possible to search for specific fields, e.g.
Searching for tags onlyEvery search result displays the tags of a file and related tags to the query. Clicking on one tag searches for this tag only. Alternatively, check the
Searching for file path onlyIf checking Open a file in your local editorUnder the tags of a search result is the path of that file. By clicking on the link it can be opened in your default editor. The command to run the path with is defined in the configuration with Last searchesOn the bottom of the search result page is a list of the last searches. They are stored in a plain text file named SchemaThe search schema is defined in Tip: changing between directories without rebuilding the indexIf you have different markdown files that you don't want to belong to the same index, it is quite easy to switch between different locations without the need to rebuild the index each time. Arrange your Now when changing the Now you point the search engine to your local folder by running: If you want to learn more about the project, have a look at the related post: http://www.bernhardwenzel.com/blog/2015/08/17/how-to-have-an-elephant-brain/ 
|

2023-10-27
2022-08-15
2022-08-17
2022-09-23
2022-08-13

六六分期app的软件客服如何联系?不知道吗?加qq群【895510560】即可!标题:六六分期
今天小编告诉大家如何处理win10系统火狐flash插件总是崩溃的问题,可能很多用户都不知

今天小编告诉大家如何对win10系统删除桌面回收站图标进行设置,可能很多用户都不知道
今天小编告诉大家如何对win10系统电脑设置节能降温的设置方法,想必大家都遇到过需要
我们在使用xp系统的过程中,经常需要对xp系统无线网络安装向导设置进行设置,可能很多
今天小编告诉大家如何处理win7系统玩cf老是与主机连接不稳定的问题,可能很多用户都不
电脑对日常生活的重要性小编就不多说了,可是一旦碰到win7系统设置cf烟雾头的问题,很
我们在日常使用电脑的时候,有的小伙伴们可能在打开应用的时候会遇见提示应用程序无法
今天小编告诉大家如何对win7系统打开vcf文件进行设置,可能很多用户都不知道怎么对win
今天小编告诉大家如何对win10系统s4开启USB调试模式进行设置,可能很多用户都不知道怎








请发表评论