









开源软件名称(OpenSource Name):snap-stanford/ogb开源软件地址(OpenSource Url):https://github.com/snap-stanford/ogb开源编程语言(OpenSource Language):Python 100.0%开源软件介绍(OpenSource Introduction):
OverviewThe Open Graph Benchmark (OGB) is a collection of benchmark datasets, data loaders, and evaluators for graph machine learning. Datasets cover a variety of graph machine learning tasks and real-world applications. The OGB data loaders are fully compatible with popular graph deep learning frameworks, including PyTorch Geometric and Deep Graph Library (DGL). They provide automatic dataset downloading, standardized dataset splits, and unified performance evaluation.
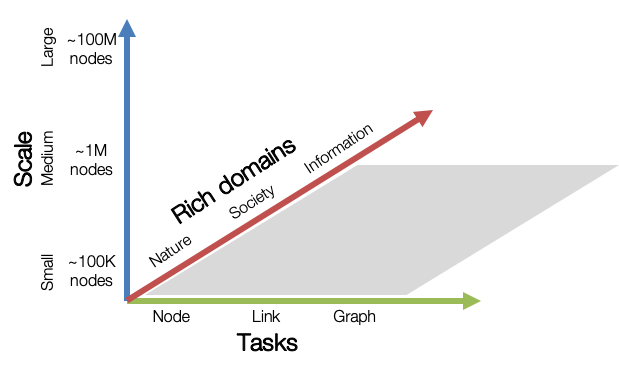
OGB aims to provide graph datasets that cover important graph machine learning tasks, diverse dataset scale, and rich domains. Graph ML Tasks: We cover three fundamental graph machine learning tasks: prediction at the level of nodes, links, and graphs. Diverse scale: Small-scale graph datasets can be processed within a single GPU, while medium- and large-scale graphs might require multiple GPUs or clever sampling/partition techniques. Rich domains: Graph datasets come from diverse domains ranging from scientific ones to social/information networks, and also include heterogeneous knowledge graphs.
OGB is an on-going effort, and we are planning to increase our coverage in the future. InstallationYou can install OGB using Python's package manager Requirements
Pip installThe recommended way to install OGB is using Python's package manager pip: pip install ogbpython -c "import ogb; print(ogb.__version__)"
# This should print "1.3.3". Otherwise, please update the version by
pip install -U ogbFrom sourceYou can also install OGB from source. This is recommended if you want to contribute to OGB. git clone https://github.com/snap-stanford/ogb
cd ogb
pip install -e .Package UsageWe highlight two key features of OGB, namely, (1) easy-to-use data loaders, and (2) standardized evaluators. (1) Data loadersWe prepare easy-to-use PyTorch Geometric and DGL data loaders. We handle dataset downloading as well as standardized dataset splitting. Below, on PyTorch Geometric, we see that a few lines of code is sufficient to prepare and split the dataset! Needless to say, you can enjoy the same convenience for DGL! from ogb.graphproppred import PygGraphPropPredDataset
from torch_geometric.loader import DataLoader
# Download and process data at './dataset/ogbg_molhiv/'
dataset = PygGraphPropPredDataset(name = 'ogbg-molhiv')
split_idx = dataset.get_idx_split()
train_loader = DataLoader(dataset[split_idx['train']], batch_size=32, shuffle=True)
valid_loader = DataLoader(dataset[split_idx['valid']], batch_size=32, shuffle=False)
test_loader = DataLoader(dataset[split_idx['test']], batch_size=32, shuffle=False)(2) EvaluatorsWe also prepare standardized evaluators for easy evaluation and comparison of different methods. The evaluator takes from ogb.graphproppred import Evaluator
evaluator = Evaluator(name = 'ogbg-molhiv')
# You can learn the input and output format specification of the evaluator as follows.
# print(evaluator.expected_input_format)
# print(evaluator.expected_output_format)
input_dict = {'y_true': y_true, 'y_pred': y_pred}
result_dict = evaluator.eval(input_dict) # E.g., {'rocauc': 0.7321}Citing OGB / OGB-LSCIf you use OGB or OGB-LSC datasets in your work, please cite our papers (Bibtex below). 
|

2023-10-27
2022-08-15
2022-08-17
2022-09-23
2022-08-13

六六分期app的软件客服如何联系?不知道吗?加qq群【895510560】即可!标题:六六分期
今天小编告诉大家如何处理win10系统火狐flash插件总是崩溃的问题,可能很多用户都不知

今天小编告诉大家如何对win10系统删除桌面回收站图标进行设置,可能很多用户都不知道
今天小编告诉大家如何对win10系统电脑设置节能降温的设置方法,想必大家都遇到过需要
我们在使用xp系统的过程中,经常需要对xp系统无线网络安装向导设置进行设置,可能很多
今天小编告诉大家如何处理win7系统玩cf老是与主机连接不稳定的问题,可能很多用户都不
电脑对日常生活的重要性小编就不多说了,可是一旦碰到win7系统设置cf烟雾头的问题,很
我们在日常使用电脑的时候,有的小伙伴们可能在打开应用的时候会遇见提示应用程序无法
今天小编告诉大家如何对win7系统打开vcf文件进行设置,可能很多用户都不知道怎么对win
今天小编告诉大家如何对win10系统s4开启USB调试模式进行设置,可能很多用户都不知道怎










请发表评论